Matsubo Tech Blog
Matsubo Tech Blog会議の録音を ElevenLabs Scribe で自動 transcribe する CLI を Go で作った — vmt

概要
macOS Voice Memos に溜まった会議録音を ElevenLabs Scribe で一気に文字起こしできる CLI vmt を作りました。
- 録音 DB (
CloudRecordings.db) を直接読み、ファイルを一覧・バッチ transcribe - 話者分離 (
diarize) 込みで txt / md / json / csv / xml を同時出力 - bubbletea TUI、cobra CLI、Alfred / Raycast 連携、
fsnotify+launchdで録音→自動 transcribe - シングルバイナリ (
go build)、macOS 専用、MIT License
きっかけ:会議のたびに ElevenLabs に手動アップロードする作業が面倒
手元の Mac で会議を録音することが多いのですが、録音後のフローが毎回同じでダルい。
- Voice Memos を開く
- 録音を選んでエクスポート
- ElevenLabs の Web UI にアップロード
- transcribe が終わったら結果を DL
- 次の録音で同じことを繰り返す
会議の文字起こしに限れば、ElevenLabs Scribe の話者分離 (diarize) は現状最強クラスです。日本語でも speaker_0 / speaker_1 をちゃんとグループ化してくれて、他の STT サービスを何個か試した結果、会議用途では ElevenLabs 一択、という結論でした。
それだけ頼りにしているのに、使うたびに手動アップロードしてるのが馬鹿らしい。「録音した瞬間に、ローカルに .md が落ちてる」状態にしたい。これが動機です。
本当にやりたかったこと — AI エージェントから一発で議事録共有
「ローカルに .md を落とす」のはあくまで第一歩で、本命のゴールは AI エージェント (Claude Code / Raycast AI / MCP 経由の LLM) から自然言語で議事録を共有する ことでした。具体的にはこういうワークフロー:
「最新の Voice Memo の録音を会議参加者に Google Docs で共有しておいて」
と言うだけで、エージェントが:
vmtで最新の録音を transcribe (話者分離込みの.mdを生成)gws(Google Workspace CLI) で Google Docs を新規作成・書き込み- Google Calendar の該当イベントから参加者リストを引く (録音時刻の前後30分に自分が参加者のイベントを探せば特定できる)
- そのままイベント参加者全員に Docs を share、リンクを Slack or メールで送信
ここまで全部自動で終わる。人間は「会議が終わったので共有しといて」と言うだけ。参加者リストは Google Calendar が持っているので、共有範囲の判断も自動化できます。
この全体像の中で、入口である Voice Memos → テキスト化のステップだけ「自動化されていないボトルネック」だったのが vmt を作った理由です。CLI として叩ける形で出しておけば、AI エージェント側から見ると「コマンドが 1 個増えただけ」で、あとは LLM の tool use で他の CLI (gws, gh, slack-cli 等) と自由に組み合わせられる。
vmt watch で常駐させて録音→自動 transcribe まで回しておけば、AI エージェントに話しかけた時点で既に .md は存在していて、残タスクは「共有」だけ、というところまで短縮できます。
最初は Python で書いていた
実は最初は Python で書いていました。requests + click で ElevenLabs API を叩くだけのスクリプト。30行ぐらいで動いたので、しばらくはこれで満足していました。
不満が出てきたのはエコシステム連携のとき:
- Raycast の Script Command から呼びたい — Python スクリプトだと venv や依存パッケージのロード時間でもっさりする
- Alfred Workflow のトリガーに繋ぎたい — 依存パッケージ周りの問題をユーザー環境で起こしたくない
launchdの Agent として常駐させたい — Python daemon は管理が面倒
「インストールも一発で終わらせたい」「依存関係をゼロにしたい」「どこから呼んでも即レスポンスが欲しい」—— この3点を同時に満たすには シングルバイナリ が必要で、Go に書き直しました。
結果: go build 1発で 8MB の Mach-O が出て、Raycast でも Alfred でも launchd でも起動コスト ~20ms。正解でした。
設計のポイント
Voice Memos の SQLite DB を直接読む
Voice Memos は録音メタデータを Core Data の SQLite DB (~/Library/Group Containers/group.com.apple.VoiceMemos.shared/Recordings/CloudRecordings.db) に持っています。テーブルは ZCLOUDRECORDING:
// 主要な列だけ// Z_PK INTEGER — primary key// ZENCRYPTEDTITLE TEXT — タイトル(平文、命名が紛らわしい)// ZPATH TEXT — "20260415 113326-ABCD1234.m4a"// ZDURATION REAL — 秒// ZDATE REAL — Core Data timestamp (Unix + 978307200)// ZEVICTIONDATE REAL — NULL なら生存、値ありなら「Recently Deleted」modernc.org/sqlite (pure Go、CGo 不要) でアクセス。Core Data タイムスタンプのオフセット 978307200 は 2001-01-01 00:00:00 UTC の Unix 秒。
削除済み録音の扱いだけは罠で、ZEVICTIONDATE が NULL でないものは .m4a が残っていても「削除予定」扱いなので、WHERE ZEVICTIONDATE IS NULL で除外が必須でした。これを入れ忘れると、削除したはずの録音が vmt の一覧にゾンビ表示されます。
Pluggable な Engine interface
ElevenLabs 固有のロジックを外に追い出せるよう、STT エンジンは interface で抽象化:
type Engine interface { Name() string Transcribe(ctx context.Context, audioPath string, opts TranscribeOptions) (*TranscribeResult, error) EstimateCost(durationSeconds float64) float64}将来 Whisper や Google Cloud STT を追加するときは internal/engine/<name>/client.go を書いて registry に Register するだけ。
現状は ElevenLabs Scribe v1 ($0.40/hour) と v2 ($0.22/hour) のみ対応。v2 は新しい分安いのでデフォルト。
マルチフォーマット同時出力
1回の API 呼び出しから txt / md / json / csv / xml を同時生成:
Meeting.txt: [00:15] speaker_0: こんにちは [01:23] speaker_1: どうも
Meeting.md: - **00:15** speaker_0: こんにちは - **01:23** speaker_1: どうも
Meeting.json: { "segments": [...], "engine": "elevenlabs", ... }どれか1個あれば他を使わない人もいるし、人間用 (md) と機械用 (json) の両方欲しい人もいる。実装コストは低いので全部出す方針にしました。
TUI (bubbletea)
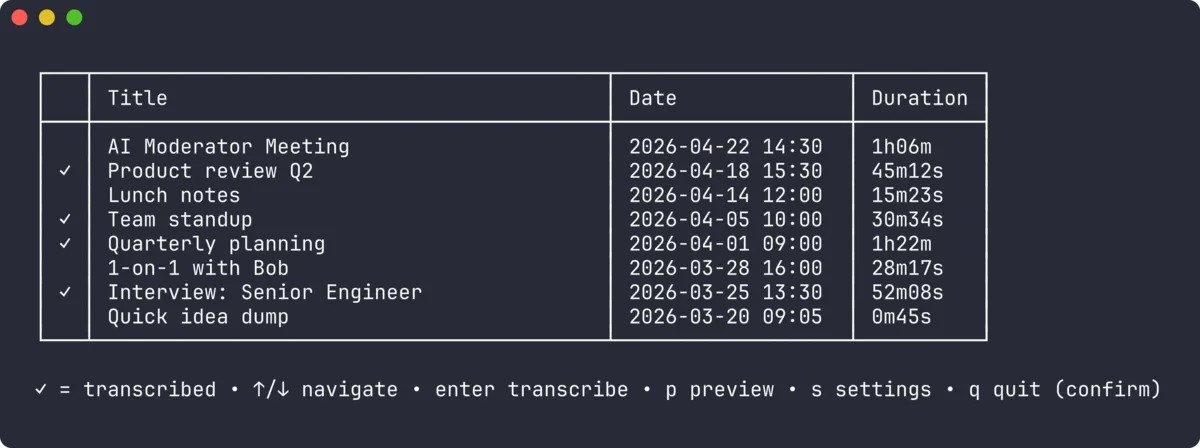
vmt tui で対話的にアクセスできます。画面は 5つ:
- list — 録音一覧。
✓マーク付きで transcribe 済みかどうか一目で分かる - confirm — 選択した録音の料金見積りと y/n 確認
- progress — spinner + 経過秒
- preview — transcribe 結果を表示、
cキーで pbcopy、←/→でフォーマット切替 - settings — エンジン・モデル・言語の確認
- quit confirm —
q/Ctrl+Cで「Quit vmt? [y/n]」
bubbletea は状態遷移が綺麗に書けて気持ちよかったです。画面遷移は message-passing なので、Update() に集約して managing の headache が少ない。
エコシステム連携
Alfred Script Filter
$ vmt alfred [query]{"items":[{"uid":"...","title":"会議 4/22","subtitle":"2026-04-22 14:30 (1h06m)","arg":"20260422_143000.m4a","icon":{"path":"icons/transcribed.png"}, ...}]}Alfred Workflow から /usr/local/bin/vmt alfred {query} を Script Filter として呼ぶと、録音一覧がキーワード検索可能な形で返ります。Enter で transcribe、Cmd+Enter で preview。
Raycast Script Commands
Raycast ユーザー向けに 5 つの Script Command を同梱 (raycast/ ディレクトリ):
| Command | 機能 |
|---|---|
| Transcribe All Pending | 未 transcribe な録音をバッチ処理 |
| Copy Latest Transcription | 最新の .txt をクリップボードへ |
| List Voice Memos Recordings | 録音一覧を表示 |
| Open Voice Memos TUI | Terminal.app で vmt tui 起動 |
| Toggle Watch Agent | launchd watch agent の install / uninstall |
Raycast → Settings → Extensions → Script Commands → Add Directory で raycast/ を指定するだけで使えます。
vmt watch + launchd
これが一番の目玉機能。fsnotify で ~/Library/Group Containers/group.com.apple.VoiceMemos.shared/Recordings/ を監視して、新しい .m4a が出現したら 2秒 debounce (Voice Memos は incremental write) 後に自動 transcribe → macOS 通知で知らせる。
$ vmt watch --installInstalled: /Users/matsu/Library/LaunchAgents/com.matsubo.vmt.watch.plistvmt watch will start automatically on login.Mac 起動時に自動で走り、会議が終わって録音を止めた数分後には ~/Downloads/voice-memo-transcription/ に .md と .json が落ちてる、という状態。これ最高に便利です。
ハマりどころ
ZEVICTIONDATE 列の存在
上に書いた通り、Voice Memos の「削除」はソフトデリート。実体 .m4a は残り、DB 行には削除予定時刻がセットされるだけ。初回実装では WHERE ZEVICTIONDATE IS NULL を入れ忘れていて、削除したはずの録音が一覧に出続けるバグがありました。
テストで ZEVICTIONDATE 列を持つ fixture を用意して、削除行が List 結果に含まれないことを確認しています。
DB が一時的に消える現象
ある日 vmt list を動かしたら no Voice Memos recordings found が出たので調べると、CloudRecordings.db 本体は消えていて .db-shm と .db-wal だけ残っている状態。macOS Voice Memos が DB 再構築中だったようです。.m4a は普通に残っている。
仕方ないので、DB がなくても .m4a をスキャンしてファイル名から日時をパース (20220215 184033-HASH.m4a 形式) するフォールバックを実装しました。duration は不明になるのと、ユーザー命名タイトルは失われますが、少なくとも「録音があるのに表示されない」状態は避けられます。
golangci-lint が Go 1.25 に対応していない
CI で golangci-lint を回していたら the Go language version (go1.24) used to build golangci-lint is lower than the targeted Go version (1.25.0) で失敗。golangci-lint v1.64.8 が Go 1.24 ビルドで、go.mod の go 1.25.0 を解析できない。
深追いせず、CI の lint ステップは go vet ./... に置き換えました。go vet は stdlib 同梱なので Go バージョン問題は起きません。
開発プロセス — Claude Code で計画→実装→レビューを自律実行
余談として開発手法も残しておきます。このプロジェクトは実装の大部分を Claude Code の superpowers プラグイン で進めました。ざっくり:
superpowers:writing-plansで仕様から詳細な実装プランを生成 (12 タスク、各タスクに TDD ステップと完全なコード例が入る)superpowers:subagent-driven-developmentでタスクごとに subagent を dispatch → 実装 → 自動で spec compliance review と code quality review の2段階でチェック- レビューで指摘された issue はそのまま次のラウンドで fix に回される
手動で書いたのは、設計判断と方向性の修正 (ZEVICTIONDATE に気づいた、filesystem scan fallback を入れる、etc) が中心で、実装コードのほとんどは subagent が書きました。22 コミットできたものを最終的に sekkei / jissou / test の 3 コミットに squash して main に force push、v0.0.1 としてリリース。
全体を通して「人間は要件と設計に集中、実装は委譲、レビューで品質担保」という流れが綺麗に回りました。もちろん Voice Memos の SQLite スキーマみたいなドメイン知識は subagent に事前に仕込んで渡す必要があったり、CI 失敗のデバッグは自分でやる必要があったりはしますが。
リポジトリ
ソース: github.com/matsubo/voice-memo-stt
git clone https://github.com/matsubo/voice-memo-stt.gitcd voice-memo-sttmake buildsudo cp bin/vmt /usr/local/bin/
export ELEVENLABS_API_KEY=sk-xxxxxvmt tuiMIT License、macOS 専用。ElevenLabs API key が必要です。
Homebrew tap は未公開 (brew install matsubo/tap/vmt は今後)。Issue / PR 歓迎します。