Matsubo Tech Blog
Matsubo Tech BlogCoolify環境のログ管理と障害対応:Docker + Zabbix + Discordで運用を回す
概要
- Docker json-file ドライバのログローテーション設定で、ディスク溢れを防止
- Zabbix → Discord Webhookで障害をリアルタイム通知
- 実際に発生した障害(MySQL停止、swap圧迫、SSL証明書エラー)の対応事例
- journald + docker logs + Zabbixの3層で「何が起きているか」を把握する運用フロー
第6回でリソース監視、第7回でバックアップ戦略を構築した。最後のピースは**「何か起きたとき、どう気づいて、どう対応するか」**。
ログの全体像
Coolify環境には3つのログソースがある。
| レイヤー | ソース | 確認方法 | 主な用途 |
|---|---|---|---|
| OS | systemd journald | journalctl -u <service> | cloudflared、zabbix-agent2 |
| コンテナ | Docker json-file | docker logs <container> | アプリログ、DBログ |
| 監視 | Zabbix | Web UI / API | トリガー、アラート履歴 |
この3つを組み合わせて「何が起きているか」を把握する。
Docker ログローテーション
デフォルトの罠
Dockerのデフォルトログドライバは json-file で、ローテーションなし。放置するとログファイルが際限なく膨らんでディスクを食い潰す。30+コンテナが動いている環境では致命的。
設定
/etc/docker/daemon.json でグローバルに設定済み。
{ "log-driver": "json-file", "log-opts": { "max-size": "10m", "max-file": "3" }}| 設定 | 値 | 意味 |
|---|---|---|
max-size | 10m | 1ファイル最大10MB |
max-file | 3 | 最大3ファイル保持 |
| コンテナあたり上限 | 30MB | 10MB × 3ファイル |
| 全体上限(30コンテナ) | 約900MB | 十分に制御可能 |
この設定がないと、ログが活発なコンテナ(Railsアプリ、Traefik)で数GBに膨らむことがある。
確認方法
# 各コンテナのログサイズ確認sudo du -sh /var/lib/docker/containers/*/アラート通知:Zabbix → Discord
なぜDiscordなのか
| 通知先 | コスト | セットアップ | モバイル通知 |
|---|---|---|---|
| 無料 | SMTPサーバ必要 | △ | |
| Slack | 無料枠あり | Webhook簡単 | ✅ |
| Discord | 無料 | Webhook簡単 | ✅ |
| Telegram | 無料 | Bot作成必要 | ✅ |
| PagerDuty | 有料 | エンタープライズ向け | ✅ |
個人開発者にとって、Discordが最適解。無料、Webhook作成が30秒、スマホ通知あり、メッセージの色分け(Severity)にも対応。
Discord Webhook の設定
- Discordサーバーで「サーバー設定 → 連携サービス → ウェブフック」
- 「新しいウェブフック」を作成。チャンネルは
#alerts等 - Webhook URLをコピー
Zabbix側の設定
ZabbixにはDiscordメディアタイプが標準搭載されている。
- Alerts → Media types → Discord を開く(status: Enabled)
- Trigger actionsを作成:
- Alerts → Actions → Trigger actions → Create action
- Conditions: Trigger severity >= Warning
- Operations: Send to Discord(Admin userのMedia設定にDiscord Webhook URLを追加)
通知の内容
Zabbixの標準Discord Webhookは、Severity に応じた色分け付きで通知される。
| Severity | 色 | 例 |
|---|---|---|
| Information | 青 | コンテナ再起動検知 |
| Warning | 黄 | swap使用率 > 50% |
| Average | オレンジ | コンテナ停止 |
| High | 赤 | MySQLダウン |
| Disaster | 濃赤 | サーバー到達不能 |
実際に発生した障害事例
監視を入れたことで、実際にいくつかの問題を検知・対応できた。
事例1: MySQL停止(High)
問題: MySQL: Service is downホスト: gmk継続時間: 6日以上WordPressの旧MySQL(移行前のレガシーDB)が停止していた。Coolifyのリソース画面でも Exited 表示。現在は使っていないDBなので、意図的に停止したまま放置しているが、監視がなければ「本番DBが落ちていた」場合に気づけなかった。
対応: Zabbixでこのトリガーをacknowledgeし、不要ならコンテナを削除。
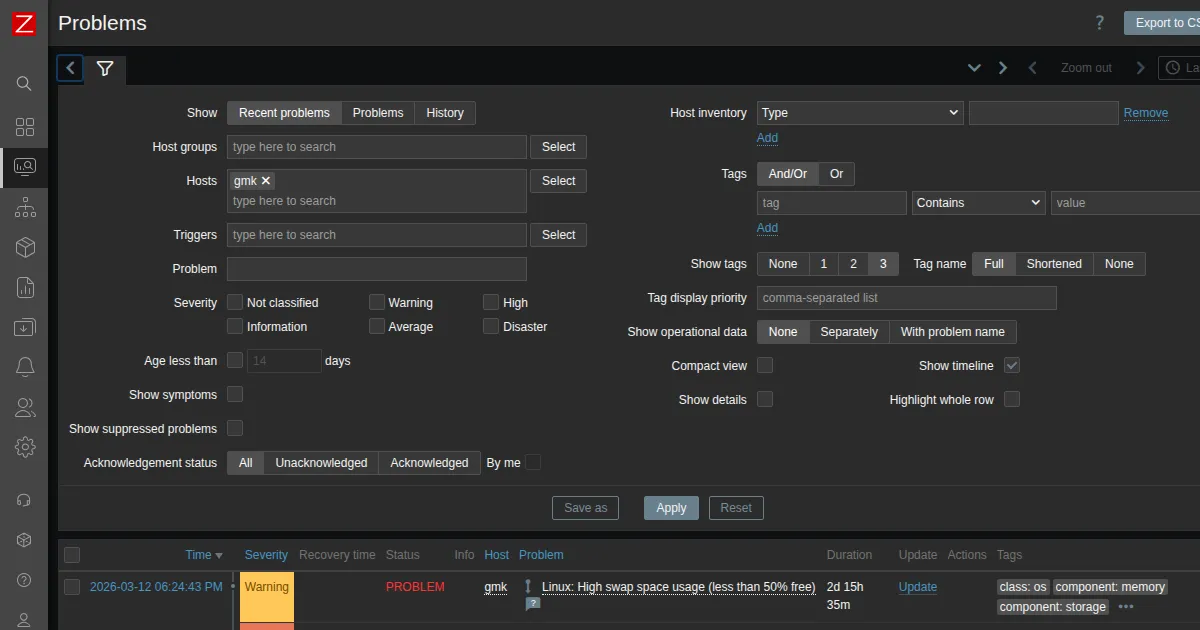
事例2: swap圧迫(Warning)
問題: Linux: High swap space usage (less than 50% free)ホスト: gmk継続時間: 2日以上32GB RAMの環境でswapが圧迫されている。第6回で発見したcoolify-sentinelの5.2GBメモリ使用が主因。30+コンテナの合計メモリ使用量がRAMを超え始めている。
対応: sentinel以外のメモリ消費を確認し、不要なコンテナを停止。長期的にはRAM増設(64GB)を検討。
事例3: SSL証明書エラー(Traefik)
Traefik(coolify-proxy)のログに繰り返しエラー。
ERR Unable to obtain ACME certificate for domains domains=["coolify.teraren.com"] error="too many failed authorizations"原因: Cloudflare Access(Zero Trust)でcoolify.teraren.comを保護しているため、Let’s EncryptのHTTP-01チャレンジがCloudflare Accessのログインページにリダイレクトされて認証に失敗する。
対応: Cloudflare Tunnel経由のサービスはCloudflare側でSSL終端するため、Traefik側のLet’s Encrypt証明書は不要。第4回で説明した通り、CoolifyのドメインはHTTPで設定する。このエラーは無視して良い。
事例4: コンテナの異常再起動
問題: Docker: Container /immich: Container has restarted 11 timesホスト: gmkImmich(写真管理)のコンテナが11回再起動していた。Coolifyのリソース画面でも (11x restarts) と表示。
対応: docker logs でImmichのログを確認。メモリ不足でOOM Killerに殺されていた。Immichのメモリ制限を調整。
障害対応フロー
障害が発生したときの対応手順を標準化しておく。
1. Discord通知を受信 ↓2. Zabbix Web UIで詳細確認 - どのホスト?どのトリガー?いつから? ↓3. ログ確認 - OS系: journalctl -u <service> --since "1 hour ago" - コンテナ系: docker logs --tail 100 <container> - Traefik: docker logs coolify-proxy --tail 50 ↓4. 対応 - コンテナ再起動: docker restart <container> - Coolify経由: Coolify UI → アプリ → Restart - 設定変更: Coolify UI or MCP経由 ↓5. 確認 - Zabbixでトリガーが解消されたか確認 - アプリにアクセスして正常動作を確認よく使うログコマンド
# === OS サービス ===# cloudflaredのログ(Tunnel障害時)journalctl -u cloudflared --since "1 hour ago" --no-pager
# zabbix-agentのログjournalctl -u zabbix-agent2 --since "1 hour ago" --no-pager
# === Docker コンテナ ===# 特定コンテナの最新ログdocker logs --tail 100 <container_name>
# リアルタイムログ(Ctrl+Cで終了)docker logs -f <container_name>
# タイムスタンプ付きdocker logs --tail 50 -t <container_name>
# === 横断的な確認 ===# 全コンテナの状態一覧docker ps --format "table {{.Names}}\t{{.Status}}\t{{.RunningFor}}"
# 異常終了したコンテナdocker ps -a --filter "status=exited" --format "table {{.Names}}\t{{.Status}}"
# ディスク使用量docker system dfCoolify UIのログ機能
CoolifyのWeb UIにもログ表示機能がある。各アプリの詳細画面 → Logsタブで、コンテナログをブラウザから確認できる。
| 方法 | 用途 |
|---|---|
| Coolify UI → Logs | ブラウザから手軽に確認。外出先でも |
docker logs | 詳細な検索。grep等でフィルタ |
| Zabbix | 異常検知・アラート。過去のイベント履歴 |
普段はZabbixのアラートで異常に気づき、Coolify UIかdocker logsで詳細を確認する流れ。
まとめ
| 要素 | 構成 | 目的 |
|---|---|---|
| ログローテーション | Docker json-file 10MB×3 | ディスク溢れ防止 |
| アラート通知 | Zabbix → Discord Webhook | リアルタイムで障害検知 |
| ログ確認 | journald + docker logs + Coolify UI | 原因調査 |
| 障害対応 | 標準化されたフロー | パニックせずに対応 |
セルフホストの運用は「監視 → アラート → ログ確認 → 対応」のサイクルを回すこと。Zabbix(第6回)で監視し、Discordで通知を受け、docker logsで原因を調べ、Coolify UIかMCPで対応する。バックアップ(第7回)があれば、最悪の場合でも復旧できる。
このシリーズで構築した環境の全体像:
GitHub Push → Coolify(自動ビルド&デプロイ) ↕ Cloudflare Tunnel(外部公開) ↕ Zabbix(監視) → Discord(通知) ↕ mergerfs + snapraid(バックアップ)Vercel月額$42から始まった話が、月額$0で監視・バックアップ・アラート通知まで揃った自宅PaaS環境になりました。
シリーズ記事
- Vercel月額$42→自宅サーバ月額$0。Coolifyで個人サービス基盤を作った話
- Coolifyインストールから「プロンプトでデプロイ」まで:Claude Code MCP実践
- Coolifyハンズオン:Hono・Go・Railsを実際にデプロイしてみる
- Cloudflare Tunnel×Coolify:自宅サーバを安全に外部公開する
- API-firstなインフラが生き残る:LLM時代のセルフホスト戦略
- ZabbixでDockerコンテナをリソース監視する:Coolify環境の可視化
- Coolify環境のバックアップ戦略:6つのDBを自動ダンプ+復旧手順
- Coolify環境のログ管理と障害対応:Docker + Zabbix + Discordで運用を回す(この記事)