Matsubo Tech Blog
Matsubo Tech Blogアンケート回答を代替するLLM個人モデルの構築と精度検証:N=1予備実験


3秒まとめ
- 自分自身の個人モデルを構築し、アンケート回答を自動化する PoC「bunshin」を実装(N=1 の予備実験)
- 答え合わせ用に伏せた 10 問(ホールドアウト)で評価: 単一選択 accuracy 71.4%(5/7)、Likert ±1 以内 66.7%(2/3)、MAE 1.0
- 自由対話チャットでは本人らしい応答が観察され、強制選択と自由生成の非対称性 が示唆された
対象読者
- 消費者調査・マーケティングリサーチの実務に携わる方
- LLM を用いた個人モデルや合成回答者(synthetic respondents)の動向に関心がある方
- 「LLM にアンケート回答を代行させる」アプローチの実現可能性を検討している方
背景:1 年半前に執筆した記事の位置づけ
1 年半前、筆者は「AI が消費者調査にもたらす未来」と題したブログ記事を執筆しました。
要旨は、定性調査・定量調査の各フェーズに AI がどのように関与し得るかを CTO の立場から整理したものです。当時は構想段階の議論にとどまり、具体的な実装には踏み込んでいませんでした。
1 年半が経過し、LLM の進展は予想を上回るものとなりました。特に、定量調査の「実査(アンケート回答収集)」フェーズの自動化 は、当時は実装可能性の低いテーマと位置付けていましたが、現時点では現実的な選択肢として論じられる水準に達しています。
実査自動化の便益
定量調査における実査とは「アンケートを配布し、回答を収集する」フェーズを指します。本フェーズはリサーチ全体の所要時間とコストの大きな部分を占め、ボトルネックとなる傾向があります。
LLM による自動化が実現すれば、利害関係者全員に便益が生じます。
graph LR A[従来の実査フロー] --> A1[アンケート設計] A1 --> A2[パネル配信] A2 --> A3[人間が回答<br/>20-30分/人] A3 --> A4[集計] B[個人モデルによる実査フロー] --> B1[アンケート設計] B1 --> B2[個人モデルに問い合わせ] B2 --> B3[LLM が回答<br/>数秒/人] B3 --> B4[集計] style A3 fill:#fdd style B3 fill:#dfd
- パネル側(回答者): アンケート回答に要する時間を削減できる
- 回収側(リサーチ会社・事業会社): 数日単位を要していたフィードバックが数十秒から数分で得られ、仮説検証サイクルが短縮される
- クライアント: 探索的リサーチを低コストで反復実施でき、本調査前にコンセプトを絞り込める
LLM 登場以前は、人間の回答パターンを高い精度でシミュレーションすることは困難でした。LLM の進展により、本アプローチが現実的な検討対象となっています。
関連研究の概観
本テーマは未踏領域と当初は想定しましたが、文献調査の結果、2022 年以降に関連研究が活発に蓄積されている領域であることが確認されました。英語学術界では “Digital Twin”、“Silicon Sample”、“Generative Agent”、“Synthetic Respondents” など複数の用語で参照されています(これらの用語と日本語の「デジタルツイン」が指す対象は必ずしも一致しないため、後述の用語注記節で整理します)。
本稿で参照する主要文献は以下の 4 本です。
| 論文 | 著者 | 主要な貢献 |
|---|---|---|
| Out of One, Many (2022) | Argyle et al. | 「Silicon Sample」概念の祖型。集団分布の再現 |
| Generative Agent Simulations of 1,000 People (2024) | Park et al. (Stanford + Google DeepMind) | 1,052 名に 2 時間のインタビューを実施。生 accuracy 約 69%、本人 self-consistency で正規化すると 約 85% |
| Twin-2K-500 (2025)(公開データセットの名称) | Toubia et al. (Columbia) | 2,058 名 × 500 問の公開ベンチマーク。13 手法を比較 |
| Digital Twins as Funhouse Mirrors (2026) | Toubia et al. | 自己批判的論文。「個人モデルは個人差を捉えていない」とする楽観論への反証 |
特筆すべきは、本領域が 現在進行中の研究分野 であり、評価方法すら統一的な合意に至っていない点です。同一データであっても評価指標を変えると精度が大きく変動します。Toubia ら の研究グループは 2025 年に公開ベンチマーク Twin-2K-500 を提示した翌年、同じデータを用いて「個人モデルは個人差を十分に再現できていない」と結論する自己批判的論文を発表しており、領域全体が安定していないことを示しています。
このような状況下で、既存研究の実装を参照しつつ独自の個人モデルを構築し評価することが、本検証の出発点です。
重要な前提: bunshin は「個人モデルによる完全代替」を志向するプロダクトではありません。海外においても業界標準は 80/20 ルール(80% の探索的リサーチを合成、20% の最終検証を実在回答者で実施)であり、bunshin も同様の方針を採用します。
用語注記:本稿の「個人モデル」と「デジタルツイン」
英語学術界では、本研究の系譜は “Digital Twin”(Toubia 2025/2026)や “Generative Agent”(Park 2024)、“Silicon Sample”(Argyle 2022)と呼ばれます。一方、日本語で「デジタルツイン」というと、Grieves (2002) を原典とする 製造業・IoT・スマートシティ系 の用法が一般的で、要件は次のように厳しい。
- 物理的実体(工場・インフラ・都市等)が存在する
- センサーから リアルタイム にデータが流れ込む
- 物理対象と仮想モデルが 双方向 に同期する
- 状態予測 → フィードバック制御に使う
経済産業省・内閣府の資料や Industry 4.0 文脈で語られる「デジタルツイン」は概ねこの意味です。
これに対して本稿が扱う対象は、人間個人の回答行動を LLM で再現するスナップショット型モデルで、物理対象もリアルタイム同期もありません。「個別対象の仮想再現」という最も抽象的な水準でしか原典定義と接続しないため、日本語で「デジタルツイン」と書くと 多くの読者が IoT・製造のイメージで読みに行ってしまい、説明コストが高くなります。
| 観点 | bunshin が該当するか |
|---|---|
| Grieves (2002) 原典定義 | × |
| 日本の一般イメージ(IoT・スマートシティ) | × |
| 英語学術界の最近の拡張的用法(Customer/Consumer Twin) | ○ |
このギャップを避けるため、本稿では 「個人モデル」 と表記し、英語学術界の Digital Twin 系研究を関連研究として参照する立場をとります。bunshin が指す対象は厳密には Grieves 定義の Digital Twin ではなく、Toubia ラボらの拡張的用法における Digital Twin(または “Customer Twin” / “Consumer Twin”)に位置付けられるものです。
合成ペルソナデータセット利用の検討
ここで自然な検討対象として、NVIDIA が公開している日本人 600 万ペルソナの合成データセット(CC BY 4.0)の利用が浮上します。
Nemotron-Personas-Japan (Hugging Face)
Nemotron-Personas-Japan の主要な特徴は以下のとおりです。
- 国勢調査ベースの人口分布に整合した 100 万レコード × 6 ペルソナ = 600 万ペルソナ
- 全 47 都道府県、1,500 以上の職業カテゴリを網羅
- 約 14 億トークン、
professional_persona/sports_persona/arts_persona/travel_persona/culinary_persona/ 統合personaの 6 種類のペルソナ記述を収録 - 商用利用可、模型崩壊(model collapse)防止やバイアス軽減用途を想定
「日本人の集団的振る舞いを LLM でシミュレーションする」というユースケースには、本データセットは十分な品質を有しています。Argyle 系の研究方向(Silicon Sampling、集団分布の再現)であれば、これは有力な基盤となります。
bunshin の目的との不整合
ただし、本検証の目的との関係では以下の問題が生じます。
1. 実在人物に対応するペルソナが存在しない
Nemotron-Personas-Japan は 完全な合成データ であり、実在人物に対応するレコードは存在しません。データセットのドキュメントにも「氏名やペルソナ記述が実在人物に類似していても、それは偶然の一致である」と明記されています。
bunshin が目指すのは「特定の本人 X の代わりに回答する個人モデル」であり、本人 X が存在しない時点で前提条件を満たしません。
2. 検証ループが原理的に成立しない
bunshin の構造的優位性は「個人モデル回答と本人回答の即時照合」にあります。実在人物を被験者として保持していれば、「この個人モデルの精度は XX%」を実データで提示できます。
合成ペルソナには照合対象となる「正解」が存在しないため、accuracy も lift も算出できません。「妥当な回答が返ってくる」状態にとどまります。
3. 動的な行動データの欠如
Nemotron-Personas-Japan に含まれるのは、デモグラ・キャリア目標・趣味・スキルといった 静的属性 です。「過去のアンケート回答履歴」「直近の購買履歴」「ブランドへの態度変化」などの 動的な行動データ は含まれません。
実在人物の継続的なアンケート回答履歴があれば、本データセットには欠落している時系列情報を利用できるため、ここが構造的な差別化要素となり得ます。
4. デモグラ条件のみでは個人精度に上限がある(Toubia 2026)
これが最も根拠の強い指摘です。Toubia 2026 “Funhouse Mirrors” は Twin-2K-500 ベンチマーク上で、「フルプロフィール(500 問以上)で構築した個人モデル」「デモグラのみで構築した個人モデル」「ベース LLM 単体」の精度を比較しています。
| 条件 | 個人精度 |
|---|---|
| ランダム | 0.629 |
| Empty persona(ベース LLM のみ) | 0.734 |
| Demographics-only | 0.746 |
| Full persona(500+ 問) | 0.748 |
すなわち、デモグラのみのペルソナは 0.746 で頭打ちとなり、500 問以上のフルプロフィールを与えても 0.002 の向上にとどまります。Nemotron-Personas-Japan のような「デモグラ + 自然言語属性」レベルの情報量では、Park 2024 が達成した 0.85 水準には原理的に到達しにくいと考えられます。
5. 文化的ニュアンスの再現困難性
日本人のアンケート回答に見られる「本音と建前の使い分け」「同調圧力下での収束」などの文化的特徴は、統計分布の整合のみでは捕捉できないと考えられます。Nemotron は分布的に「日本人らしい」回答を生成しますが、本検証で対処を要する tatemae 問題(規範的回答への収束)への対策にはなりません。
Nemotron-Personas-Japan の適合用途
ただし、本データセットが不適合と結論するわけではありません。以下の用途には極めて有用です。
- LLM の事前学習データの多様性増強(本来意図された用途)
- 集団分布レベルの市場シミュレーション(「20 代女性の購買傾向の分布を再現する」など)
- A/B テストのオフライン事前評価(個人ではなく集団のレスポンス分布の予測)
- マイノリティセグメントの探索(合成データの利点として無制限にバリエーション生成が可能)
「集団分布の再現」と「個人精度の達成」は別個の目標であり、Nemotron は前者、bunshin は後者を志向します。両者の混同は議論の妥当性を損ねます。
| 観点 | Nemotron-Personas-Japan | bunshin |
|---|---|---|
| 元データ | 合成(国勢調査ベース分布) | 実在人物の回答 |
| 規模 | 600 万ペルソナ | 被験者数に依存 |
| 検証可能性 | × 照合対象なし | ○ 本人回答との直接比較が可能 |
| 個人精度 | デモグラ上限 0.746 | Park 水準 0.85 を将来目標(本検証は N=1 予備実験で未達) |
| 集団分布の再現 | ◎ | ○ |
| コスト | 無料(CC BY 4.0) | 運用コストあり |
| 商業性 | 汎用ツール | 実在パネルベースの個別評価 |
両者は競合関係ではなく、用途を異にする関係にあります。bunshin で個人精度を確保し、Nemotron で集団分布を補完するハイブリッド構成も実装上は成立します。
本検証で構築したシステム:bunshin プロジェクト
社内コードネーム「bunshin」(分身)として、LLM 個人モデル PoC を実装しました。文献で繰り返し指摘される「LLM 個人モデルが規範的回答に収束する=建前を答える」失敗モードへの対抗を意識した命名として、内部では「Honne モデル」と呼んでいますが、これは現時点では呼称にとどまり、tatemae 対策の具体的な技術的アーキテクチャ(プロンプト・データ前処理・評価指標)は今後の課題です。
技術スタック
| レイヤー | 技術 |
|---|---|
| フレームワーク | Next.js 15 (App Router) + TypeScript |
| LLM | Claude Sonnet 4.6(Opus も比較検証中) |
| アンケート UI | 自社構築アンケートサービス(MCP 対応) |
| ストレージ | SQLite |
| デプロイ | gmk server + Coolify |
アンケート UI を独自実装する負担を避けるため、社内で開発中の MCP 対応のアンケートサービス に依存する構成としました。MCP を介して Claude Code から直接アンケートを操作できるため、検証ループを Claude Code 中心で完結させられます。
アーキテクチャ
graph TD U[ユーザ<br/>まずは筆者自身] -->|プロフィール入力| B[bunshin Next.js] U -->|65問アンケート回答| T[自社アンケートサービス] B -->|アンケート登録/取得<br/>OpenAPI| T B -->|プロフィール構造化<br/>個人モデル推論| C[Claude API] C -->|構造化プロフィール<br/>CoT 回答| B B -->|永続化| S[(SQLite)] T -->|回答データ| B B -->|lift計算<br/>ダッシュボード| D[結果ビュー] style B fill:#bdf style C fill:#fdb style T fill:#dfb
bunshin とアンケートサービスの責任分界は、UI をアンケートサービス側に寄せ、推論・評価・ダッシュボードを bunshin に閉じ込める構成です。
| 機能 | 担当 |
|---|---|
| アンケート定義の登録 | アンケートサービス |
| アンケート配信・回答 UI | アンケートサービス |
| 選択肢順序ランダマイズ | アンケートサービス |
| プロフィール入力 UI | bunshin |
| 個人モデル推論 | bunshin(Claude API) |
| バックテスト・lift 計算 | bunshin |
| 結果ダッシュボード | bunshin |
利用フロー
sequenceDiagram participant U as ユーザ participant B as bunshin participant T as アンケートサービス participant C as Claude API U->>B: ニックネーム入力 B-->>U: respondent UUID 発行 U->>T: 65 問アンケート回答<br/>(20-30 分) T->>B: callback で完了通知 B->>C: プロフィール構造化 C-->>B: 4 層構造化プロフィール loop ホールドアウト 10 問 B->>C: 個人モデル推論(CoT + Reflection) C-->>B: 回答 + reasoning end B->>B: lift 計算 B-->>U: 個人精度ダッシュボード
利用者が 10〜15 分のプロフィール入力と 20〜30 分のアンケート(65 問)回答を済ませると、自身の個人モデルが生成され、精度レポートを参照できる構成です。
検証用アンケート:コンビニ利用テーマ
検証テーマには コンビニ利用 を選定しました。選定理由は以下のとおりです。
- 回答分散が大きく、個人差が顕在化しやすい
- 多くの人が日常的に経験を有し、被験者の理解しやすさが高い
- 政治的・倫理的にセンシティブでなく、炎上リスクが低い
質問は実装時点で全 65 問 とし、bunshin の data/questions.json 上の型別内訳は以下のとおりです。
| 質問タイプ | 件数 | 評価方法 |
|---|---|---|
| 単一選択(single) | 22 問 | 完全一致率 |
| 5 段階 Likert(likert5) | 19 問 | MAE / ±1 以内一致率 |
| 6 段階頻度(frequency6) | 13 問 | MAE / ±1 以内一致率 |
| 複数選択(multi) | 3 問 | Jaccard 係数 |
| 自由記述・長文(long_text) | 7 問 | 評価対象外(学習用) |
| URL リスト(url_list) | 1 問 | 評価対象外(学習用) |
設計初期の構想は 60 問でしたが、プロフィール拡張のための長文・URL 入力など評価対象外の設問が追加された結果、最終的に 65 問となっています。
本人の回答済み 65 問のうち 10 問を 「ホールドアウト」 として取り分け、残りを学習用として個人モデルに渡します。
ホールドアウトとは: 機械学習で「モデルに学習させず、答え合わせ用に隠しておくデータ」を指す用語です。本検証では、本人の回答のうち 10 問分を個人モデルに見せずに隠し、その 10 問を個人モデルに推論で答えさせて、本人の実際の回答とどれだけ一致するかを測ります(=バックテスト)。以降「ホールドアウト 10 問」はこの「答え合わせ用に伏せた 10 問」の意味で使います。
設問の全文を以下に収録します。パイロット段階でエントロピー低(最頻値 60% 超)の設問は本番運用から除外する想定です。
検証用アンケート v1 全 60 問(クリックで展開)
A. 行動・頻度(10 問)
回答形式: 6 段階頻度
ほぼ毎日 / 週 4-6 回 / 週 2-3 回 / 週 1 回 / 月数回 / ほぼ行かない
| ID | 質問 |
|---|---|
| A1 | コンビニ全体の利用頻度 |
| A2 | セブン-イレブンの利用頻度 |
| A3 | ファミリーマートの利用頻度 |
| A4 | ローソンの利用頻度 |
| A5 | コンビニでコーヒー(淹れたて)を買う頻度 |
| A6 | コンビニで弁当を買う頻度 |
| A7 | ホットスナック(からあげ・中華まん等)を買う頻度 |
| A8 | コンビニでスイーツを買う頻度 |
| A9 | 22 時以降にコンビニに行く頻度 |
| A10 | コンビニの ATM を使う頻度 |
B. ブランド選好・行動選択(15 問)
| ID | 質問 | 回答形式 |
|---|---|---|
| B1 | メインに使うコンビニチェーン 1 つ | セブン/ファミマ/ローソン/ミニストップ/デイリー/セコマ/その他/特になし |
| B2 | セブン・ファミマ・ローソンの好み順位 | 1 位〜3 位ランキング |
| B3 | PB 商品を最もよく買うチェーン | セブンプレミアム/ファミマル/ローソンセレクト/その他/買わない |
| B4 | コーヒーが一番美味しいと思うチェーン | セブン/ファミマ/ローソン/その他/わからない |
| B5 | おにぎりが美味しいと思うチェーン | 同上 |
| B6 | スイーツが充実していると思うチェーン | 同上 |
| B7 | 弁当のレベルが高いと思うチェーン | 同上 |
| B8 | 直近 1 ヶ月で買ったカテゴリ | 複数選択(飲料/おにぎり/サンドイッチ/弁当/麺類/スイーツ/ホットスナック/酒類/雑誌・本/日用品/医薬品/コピー・FAX/チケット・収納代行/その他) |
| B9 | コンビニで最もよく使う支払い方法 | 現金/クレカ/QR コード/交通系 IC/その他電子マネー |
| B10 | アプリで最も使うコンビニチェーン | チェーン選択 + 「使わない」 |
| B11 | ホットスナックで好きなジャンル | からあげ系/中華まん/フランクフルト・アメリカンドッグ/フライ系/ナゲット/買わない |
| B12 | 好きなコンビニスイーツのジャンル | 洋菓子(プリン・シュー)/和菓子/アイス/チョコ/焼き菓子/プレミアム系/買わない |
| B13 | おでんを買った経験 | 月 1 以上/年に数回/数回だけ/一度もない |
| B14 | コンビニで「ちょい飲み」(酒+つまみ)の経験 | 月 1 以上/年に数回/数回だけ/一度もない |
| B15 | 普段のコーヒー注文 | ホット/アイス/カフェラテ系/その他/買わない |
C. 態度・価値観(20 問)
回答形式: 5 段階リッカート
強くそう思う / そう思う / どちらでもない / そう思わない / 全くそう思わない
| ID | 質問 |
|---|---|
| C1 | コンビニは私の生活に不可欠だ |
| C2 | コンビニ弁当は健康に悪い |
| C3 | PB 商品はナショナルブランドより魅力的だ |
| C4 | コンビニコーヒーはチェーンカフェ(スタバ等)と遜色ない |
| C5 | 同じ商品ならスーパーよりコンビニで買う |
| C6 | コンビニで「ちょっと贅沢」を楽しむのが好きだ |
| C7 | コンビニ食は「ちゃんとした食事」とは思えない |
| C8 | コンビニの新商品は積極的にチェックしている |
| C9 | 値段が多少高くても、コンビニの便利さに価値がある |
| C10 | コンビニで成分表示やカロリーを確認するほうだ |
| C11 | レジ前のホットスナックを衝動買いすることがある |
| C12 | 同じ用が足りるなら馴染みのチェーンを選ぶ |
| C13 | コンビニで店員に「ありがとう」と声をかけるほうだ |
| C14 | コンビニの DX(モバイルオーダー、無人決済等)を積極的に使いたい |
| C15 | コンビニで本や雑誌を立ち読みすることがある |
| C16 | コンビニ各社のキャンペーン・くじに惹かれる |
| C17 | 知らない街でもコンビニがあると安心する |
| C18 | コンビニの 24 時間営業は社会的に必要だ |
| C19 | レジ袋有料化は妥当な政策だと思う |
| C20 | コンビニ店員の仕事は社会的に過小評価されていると思う |
D. シナリオ(5 問・単一選択)
| ID | 質問 |
|---|---|
| D1 | 平日朝、出勤・通学前にコンビニで買うことが多いもの(1 つ):何も買わない / コーヒーだけ / おにぎり / サンドイッチ・パン / 弁当 / エナドリ・栄養ドリンク / その他 |
| D2 | 残業帰り 22 時、夕食をコンビニで買うなら(1 つ):弁当 / おにぎりとサラダ / カップ麺 / 惣菜とパン / 酒とつまみ / そもそも買わずに帰る |
| D3 | 旅行先のホテルにチェックイン後、コンビニに行く主な目的(複数選択):水・飲み物 / 朝食用 / 夜食 / 酒 / お土産 / 充電器・日用品 / ATM / 行かない |
| D4 | 二日酔いの朝、コンビニで真っ先に手が伸びるもの(1 つ):スポドリ系 / 水 / 味噌汁 / うどん・そば / ヨーグルト / コーヒー / おにぎり / 行かない |
| D5 | 急に小腹が空いた午後 3 時、コンビニで買うもの(1 つ):おにぎり / パン / スイーツ / カップ麺 / ナッツ・スナック / フルーツ / ホットスナック / 買わない |
E. 知識・関与度(5 問)
| ID | 質問 | 回答形式 |
|---|---|---|
| E1 | 知っている PB 名(複数選択) | セブンプレミアム / ファミマル / ローソンセレクト / 無印良品(ローソン) / 成城石井系 / 1 つも知らない |
| E2 | 認知しているコンビニのトレンド(複数選択) | 冷凍食品強化 / 高級ライン拡大 / モバイルオーダー / 無人店舗 / SDGs 対応 / 海外展開 / PB 海外輸出 / 知らない |
| E3 | 直近 1 年で話題になったヒット商品名を 1 つ自由記述 | 自由記述(思いつかない=空欄可) |
| E4 | コンビニアルバイトまたは関連業務(POS 開発、流通等)の経験 | あり / なし |
| E5 | 最近気になっている・試したいコンビニ系サービス | 自由記述(特になし可) |
F. 自由記述(5 問・バックテスト対象外、プロフィール拡張用)
| ID | 質問 | 文字数目安 |
|---|---|---|
| F1 | あなたにとってコンビニはどんな存在か | 150 字 |
| F2 | 直近 1 ヶ月で買って良かった商品とその理由 | 100 字 |
| F3 | コンビニに対する不満(なければ「特になし」) | 100 字 |
| F4 | あなたの「コンビニルーチン」があれば | 100 字 |
| F5 | もし 1 チェーンしか使えなくなったらどこを選び、なぜか | 100 字 |
筆者の提案アプローチ:4 層プロフィール表現
本節で述べる 4 層構造は、既存研究の引用ではなく 筆者独自の設計判断 です。心理学における trait/state 区分と、マーケティングの involvement/category knowledge を組み合わせたフレーミングであり、LLM 個人モデル研究における標準的な表現法ではありません。
| 層 | 内容 | 更新頻度 |
|---|---|---|
| レイヤー 1:基層(不変に近い) | デモグラ、Big Five、コア価値観、ライフステージ | 数年単位 |
| レイヤー 2:中間層 | ライフスタイル、カテゴリ関与度、ブランド親和性、メディア接触 | 年単位 |
| レイヤー 3:表層(直近文脈) | 直近の購買・回答・季節性・気分 | 週〜月単位 |
| レイヤー 4:ドメイン知識層 | カテゴリ別の知識量・経験量 | カテゴリ依存 |
過去のアンケート回答は、これらの層を 推定するための観測データ として位置付けます。回答をそのまま RAG で参照する設計では、未質問領域への外挿が弱くなるためです。
既存研究と消費者調査のレイヤー・ギャップ
この 4 層モデルを補助線として既存研究の評価対象を分類すると、興味深い構造が浮かびます。論文が報告する高い個人精度(85% 等)は、ほぼレイヤー 1 に対するものです。
| 論文 | 評価タスク | 主に問われている層 |
|---|---|---|
| Argyle 2022 | ANES(米国選挙)の投票行動 | レイヤー 1(政党所属・政治的価値観) |
| Park 2024 | General Social Survey | レイヤー 1(道徳観・宗教観・人生満足度) |
| Toubia 2025 | 人格テスト、認知能力、経済選好、ヒューリスティクス(一部 pricing も含む) | 主にレイヤー 1、一部レイヤー 2-3 |
| Toubia 2026 | creativity / labor markets / news consumption / luxury goods 等 19 タスク | レイヤー 1〜3 が混在 |
一方、実務の消費者調査が問う内容は次のような領域に属します。
- 「どのチェーンを最もよく使用するか」 → レイヤー 2(ブランド親和性)
- 「先月何を購入したか」 → レイヤー 3(直近の購買)
- 「コンビニコーヒーをどの程度の頻度で購入するか」 → レイヤー 2-3(習慣 + 直近文脈)
- 「新商品を確認するか」 → レイヤー 2-3(カテゴリ関与度)
すなわち、論文が「個人モデルは個人精度 85% で動作する」と主張する層と、消費者調査が回答を求める層は乖離していると整理できます。
graph TD subgraph "既存研究の評価対象" L1A[レイヤー1: 価値観・パーソナリティ<br/>投票行動・GSS・Big Five] end subgraph "消費者調査の対象" L2A[レイヤー2: ブランド選好・カテゴリ関与<br/>「どのチェーンを使用するか」] L3A[レイヤー3: 直近の行動<br/>「先月何を購入したか」] end L1A -.論文が高精度を<br/>報告.- ANS1[正規化精度 約 0.85] L2A -.本検証の<br/>対象.- ANS2[N=1 で予備観察のみ] L3A -.今回未評価.- ANS3[N≥5 で再検証予定] style L1A fill:#dfd style L2A fill:#fed style L3A fill:#eee
なお、Toubia 2026 が「個人差を十分に再現できない」と結論したのも、まさに luxury goods・news consumption など レイヤー 2-3 寄りのタスク を対象とした結果であり、本レイヤー・ギャップ仮説と整合的に読める観察です(同論文自体はレイヤー区分の用語を用いていないため、あくまで本稿側の解釈です)。
これは論文側の不備ではなく、「人格・価値観は変動が緩やかで学習データから捕捉しやすい」「行動・選好は表層的で変動が速く、ベース LLM の事前知識では補完できない」という構造的な差異によるものです。レイヤーが上方に位置するほど、個人モデルによる予測の困難度が増加します。
bunshin がコンビニ利用を検証テーマに選定したのは、レイヤー 2-3 を意図的に対象とするためであり、これは 既存研究の主戦場より困難な領域に踏み込んでいる ことを意味します。ただし後述する検証結果は N=1 / per-type n=3〜7 であり、本仮説の検証には全く十分でない。N≥5 規模での再評価で初めて、層仮説の傾向が読めるようになる想定です。
個人精度志向の設計判断
文献調査の結果、bunshin では 個人精度の達成(集団分布の一致ではなく、個人ごとの回答を予測する)を主たる目標としました。これに伴い、いくつかの設計判断が変わります。
- 質問選別の重要性: 全員同一の回答となる質問(低エントロピー)は精度の過大評価を招くため除外する
- プロフィールの濃度を優先: 推論プロンプトの工夫よりも、入力されるプロフィールの濃度のほうが精度寄与が大きい(Toubia 2025 の 13 手法比較からの示唆)
- 学習/テスト = 55:10: 個人モデルに渡せるサンプルが多いほど有利(自由記述・URL 等の評価対象外設問も学習側に組み込む)
- 生指標は accuracy / MAE / ±1 以内一致率: 本検証は N=1 のため、N>1 を前提とする集計指標(lift など)は本格運用せず、生指標で結果を読み解く
- Chain-of-Thought + Expert Reflection を推論プロンプトに導入(Park et al. 2024 を踏襲)
本検証は 「実装をひととおり作ってみて、自分自身を被験者にして、既存研究と比較してどのくらい精度が出るかを見てみる」 ことが目的の個人プロジェクトです。事前合意のしきい値は置かず、まず動かして数値を出し、既存研究(Park 2024 の正規化精度 0.85、Toubia 2025 の正規化 0.876 など)と並べて感覚を掴むことを優先しました。
個人モデル推論プロンプトの設計
実装したプロンプトの構造は以下のとおりです(要約版)。
[システム]あなたはユーザ X の個人モデルです。以下のプロフィールと過去の回答から、本人が回答すると推定される選択肢を1つ選んでください。推測ではなく、本人らしさの再現が目的です。
[プロフィール(構造化済み)]- デモグラ: ...- Big Five 推定: ...- ライフスタイル要約: ...- テーマ固有の背景: コンビニとの関係の自由記述から抽出 ...- 直近の発言(ブログ/SNS 抽出): ...
[同テーマでの本人の既回答(学習 55 問)]Q: ... A: ......
[今回の質問]Q: ...選択肢: ...
以下の順序で検討してください:1. プロフィールと過去回答から推察される、本テーマへの基本姿勢2. 過去回答との一貫性を保つ場合、今回の回答はどうあるべきか3. 最終回答
回答形式: { "reasoning": "...", "answer": "..." }reasoning を保存することで誤答時の事後分析を可能とし、プロンプト改善サイクルを回しやすくしています。
人格モデルには Big Five + Schwartz Values を採用しました。MBTI は心理学における再現性・予測妥当性が低いため、商用基盤への採用は不適切と判断しました。
検証結果
本 PoC では 筆者自身を被験者(N=1) とし、プロフィールとアンケート 65 問の回答を入力して自身の個人モデルを構築、ホールドアウト 10 問でバックテストを実施しました。プロンプトテンプレートを v1 → v2 → v3-reflections と段階的に改善した上での最終版(v3-reflections、Claude Sonnet 4.6)の結果を以下に示します。
⚠️ 統計的限界(重要): 本実験は N=1 のケーススタディ であり、ホールドアウトの内訳は 単一選択 n=7、Likert n=3 と極めて小さい。一般化を意図したものではなく、検出力は限定的で、ここでの数値はあくまで「方向性を見るための予備観察」です。
全体集計(ダッシュボード表示値)
bunshin のダッシュボードはユーザ単位の集計値(質問タイプ別指標の単純平均)を表示します。本検証で表示された値は以下です。
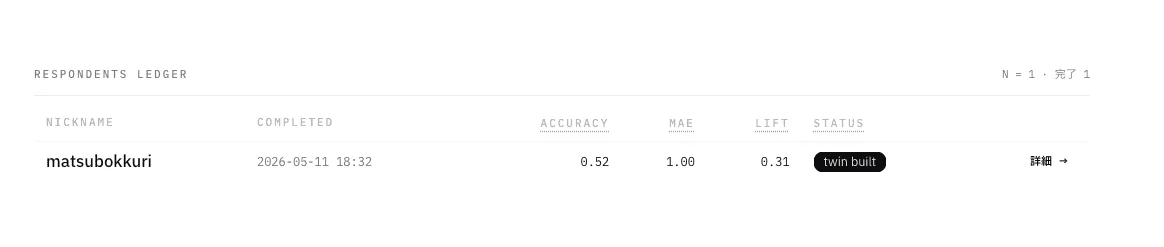
| 指標 | 値 | 備考 |
|---|---|---|
| accuracy(タイプ別平均) | 0.52 | 単一選択 0.714 と Likert 0.333 の平均 |
| MAE(Likert のみ) | 1.00 | n=3 |
質問タイプ別の生指標
| 質問タイプ | n | accuracy | MAE | ±1 以内 |
|---|---|---|---|---|
| 単一選択(single) | 7 | 0.714(5/7) | – | – |
| Likert 5 段階 | 3 | 0.333(1/3) | 1.000 | 0.667(2/3) |
ホールドアウト 10 問は B(ブランド選好)・C(態度・価値観)・D(シナリオ)から構成されており、A(6 段階頻度)系の質問は今回の分割では選出されていません。頻度系の精度評価は 未実施。今後の検証課題として残ります。
設問単位の比較
ホールドアウト 10 問について、本人回答と個人モデル回答を並列に示します。
| ID | 質問テーマ | 本人 | 個人モデル | 一致 |
|---|---|---|---|---|
| B4 | コーヒーが美味しいチェーン | セブン | セブン | ○ |
| B5 | おにぎりが美味しいチェーン | セブン | セブン | ○ |
| B7 | 弁当のレベルが高いチェーン | セブン | わからない | × |
| B10 | アプリで最も使うチェーン | セブン | セブン | ○ |
| B11 | 好きなホットスナックのジャンル | フランクフルト系 | フランクフルト系 | ○ |
| D1 | 平日朝のコンビニ購入物 | コーヒーだけ | コーヒーだけ | ○ |
| D5 | 午後 3 時の小腹購入物 | スイーツ | ホットスナック | × |
| C1 | 生活に不可欠(Likert) | 5(強くそう思う) | 5 | ○(完全一致) |
| C5 | スーパーよりコンビニ(Likert) | 4(そう思う) | 2(そう思わない) | ×(差分 2) |
| C9 | 値段より便利さに価値(Likert) | 5(強くそう思う) | 4(そう思う) | △(差分 1、±1 以内) |
正答時のリーゾニング例
bunshin は推論時の reasoning フィールドを永続化するため、ツインが各設問にどう辿り着いたかを事後解析できます。下記は D1(平日朝に出勤・通学前に買うもの) で正答(本人・ツインともに「コーヒーだけ」)した際の推論トレースです。

注目すべき点は以下です。
- 4 ステップ CoT がプロンプト指示通りに実行されている: 「基本姿勢 → 関連する reflection → 一貫性チェック → 最終回答」の構造が出力に明確に現れる
- Expert Reflection の活用: 「マーケットリサーチャー」「行動科学者」という Park 2024 由来の専門家ペルソナ観察が引用されている
- 複数設問の相互参照: A5(コーヒー購入頻度)/ A9(おにぎり)/ A10(パン)/ F2(買って良かった商品)/ F4(コンビニルーチン)など、学習側の自分の回答を ID 単位で根拠として引いている
- 4 層プロフィールの参照:
surface_layerという構造化プロフィールの層名が明示的に引用されており、設計した 4 層モデルがプロンプト文脈で機能していることを確認できる - データ内の矛盾の明示的解消:「A5=4(週 1〜2 回)は毎日ではない」「『何も買わない』より『コーヒーだけ』のほうがプロフィール記述と一致」と、テンションを言語化したうえで結論に至る
注意:リーゾニングが立派でも個人差再現の証明にはならない
このリーゾニングはエンジニアリング上は完成度が高く、一見「個人差を再現できている」根拠に見えますが、本設問はそもそも 本人の選好が明確で多数派回答とも一致しやすい設問でもあります(朝のコンビニ購入の典型回答は「コーヒーだけ」)。したがって、この正答 1 例から「ツインは個人差を捉えている」と結論はできません。リーゾニングの質と正答そのものの意義は別の観察であり、両者を区別して評価する必要があります。
誤答時のリーゾニング:「正解」が定まりにくい 2 つのパターン
誤答とされた 2 問(D5、C5)の推論トレースを見ると、accuracy 上は誤答だが、本人の認識・プロフィール全体と照らすと 「ツインが間違っているとも本人が間違っているとも言えない」 ケースがあることがわかります。それぞれが異なる評価フレーム上の限界を示唆します。
パターン 1: 単一選択フォーマットの情報損失(D5)
D5(午後 3 時の小腹で買うもの)。本人は「スイーツ(3)」、ツインは「ホットスナック(7)」を選択し、accuracy 上は誤答(DIFF)として記録されました。

推論トレースは次の論理を辿っています。
- 基本姿勢:「高タンパク・低添加物・コスパ」を軸とした選好(プロフィール由来)。スナック菓子は「コンビニだとスーパーの 2 倍」で買わない、弁当も拒否、フランクフルト・ゆで卵・ちくわ・チーズあられが好物
- 関連 Reflections: 行動科学者「カロリー / タンパク質 / コスパの 3 軸で論理的にフィルタリング」、クリエイティブプランナー「深夜・疲労時はホットスナックや簡易タンパク食品に流れる」
- 一貫性チェック: A7(ホットスナック購入頻度)= 5(月数回)、F2 でフランクフルトを TOP1 好物、C11(衝動買い)= 4。スナック菓子(選択肢 5)は高価で除外、おにぎり・パン(A9=5、A10=5)は月数回で低め、スイーツは限定的 WTP(150-250 円)あるが主選択肢としては弱い
- 最終回答: 7(ホットスナック)
ここで起きているのは、本人とツインで 異なるユースケース を選んでいる構造です。本人の「スイーツ」はメインユースケースに相当し、ツインの「ホットスナック」はたまに買うサブユースケースに相当します。リーゾニング側から見るとどちらも本人のプロフィール記述と矛盾しない選択肢で、単一選択フォーマットがその両立を許さないために DIFF 判定となっただけ、とも整理できます。
ここで顕在化しているのは、「ground truth = 本人のアンケート単一選択」という前提そのものの脆さ です。
- 単一選択フォーマットの情報損失:「午後 3 時に買うもの(1 つ)」という強制選択は、実際の購買行動の 状況依存性 を 1 つのカテゴリに圧縮する。本人は「だいたいスイーツ、たまにホットスナック、コンディションによって変わる」と認識しているかもしれないが、それを 1 つに丸めるとメインケースの「スイーツ」が出てくる
- 本人の回答自体が完全な真値ではない: アンケート回答時の気分・直前の食事・思いついた典型例などのノイズで、本人の回答も揺らぐ。ツインが本人プロフィール全体と整合するサブケースを出した結果、それが本人の単発回答(メインケース)と一致しないことは、ツインが間違っているとも本人が間違っているとも言えない
- リーゾニングが「本人らしい」のに DIFF 判定される: 本ケースでツインの推論は本人の好み・態度の一面を的確に把握しており、別の日・別の状況で本人が D5 を回答すれば「ホットスナック」を選ぶ可能性も十分にある
パターン 2: アンケート範囲の制約(C5)
C5(同じ商品ならスーパーよりコンビニで買う)。本人は「4(そう思う)」、ツインは「2(そう思わない)」を選択し、差分 2 の誤答として記録されました。
ここで起きているのは、プロフィール入力に被験者の価値観全体が含まれていなかった ことに起因する誤答です。本検証のアンケートは「コンビニ利用」に閉じた設問群で、被験者のコンビニ 以外 のライフスタイル(コスパ重視の価値観に基づき、スーパー・EC で安いものを買いだめする習慣)は学習データに含まれていません。
ツインは限定的なプロフィールから「コスパ重視」のシグナルを拾い、論理的に「同じ商品ならコンビニ(割高)より外(安い)を選ぶはず」と推論したと考えられます。これは コスパ重視という価値観を部分的にだけ知っている 状態での合理的推論で、内部論理としては正しいが、本人の実態(「コンビニ買いは便利さ目的でカテゴリを限定し、安い商品はスーパー / EC で別途まとめ買いする」という運用)には届いていません。
つまり、
- アンケート範囲がテーマに閉じていることが個人モデル精度の天井になる: コンビニアンケートだけからは、コスパ重視の価値観が「コンビニでどう発現するか」までは推察できても、「コンビニ外でどう発現するか」の文脈は学習できない
- 本人の価値観の全体像が欠けたまま部分回答だけ推論する構造: ツインはプロフィール記述(自由記述 F1〜F5、Big Five 推定など)からしか被験者像を再構成できず、テーマ外のライフスタイル情報は構造的に取り込めない
- より広範なプロフィール質問が必要: コンビニというテーマに閉じた質問だけでなく、テーマ横断的に被験者の価値観・ライフスタイルを把握する設問群(コスパ志向の発現先、買い物全体の優先順位など)が、個人モデル精度の改善には効きそう
D5 と異なり、C5 のケースは 本人の回答(4)が「ツインに不足している情報」を反映した結果として正しい 可能性が高く、ツインの「2」は 観測されていない部分を補えなかった結果 と整理できます。
評価への含意(D5・C5 共通)
両ケースが示唆するのは、accuracy は 個人モデルの本質的精度を過小評価しうる ということと、評価フレームの設計そのものが今後の検討課題 ということです。
- 状況依存質問では accuracy が下振れする構造的バイアス(D5 系): D2、D5 のようなシナリオ質問は、本人の中でも「正解」が 1 つに定まらない。にもかかわらず単一選択で正誤を測ると、ツインがまっとうに推論しても DIFF になりうる
- テーマ外プロフィール情報の欠落(C5 系): アンケートが特定テーマに閉じていると、テーマ外の価値観・ライフスタイル情報がプロフィールに入らず、ツインは部分像から推論せざるをえない
- 複数回答や尤度回答が必要かもしれない:「最もよく買うもの/たまに買うもの」のように複数選択を許容するフォーマットや、選択肢ごとに確率を出させる尤度回答のほうが、ツインの推論能力を正当に評価できる可能性
- Self-consistency 計測の重要性が増す: 本人自身の再回答とのブレを計測すれば、「ツインの DIFF が本人のブレの範囲内か」を切り分けられる。今回未測定だが、N≥5 規模での再評価では必須
すなわち、本実験で観察された誤答 2 ケースは、いずれも 「ツインは負けたが本人も完璧ではない/本人の真の価値観をアンケートが捕捉できていなかった」可能性を示唆する観察 であり、評価指標と設問設計の両方が今後の検討課題であることを示しています。
考察
単一選択:5/7 正解だが個人差再現の評価は保留
単一選択 7 問のうち 5 問正解は数値だけ見れば一定水準ですが、N=1 の本実験では「個人差を再現できているか/単に多数派回答と一致しただけか」の切り分けはできません。被験者を増やして多数派回答ベースラインが意味を持つ状態になって初めて評価可能になります。
設問単位で見ると、正答 5 問(B4 コーヒー、B5 おにぎり、B10 アプリ、B11 ホットスナック、D1 朝の購入)は、いずれもメインで使っているコンビニや明確な選好に関連する設問であり、プロフィールに含まれる情報を直接的に反映した結果と考えられます。
誤答 2 問は性質が異なります。前節「誤答時のリーゾニング」で詳述したとおり、B7 はプロフィール明示性の不足(本人の評価軸が学習データに明示されていなければ「不明」と返す)、D5 は単一選択フォーマットの情報損失(メインケースとサブケースが両立できない)に起因する誤答です。
Toubia 2026 “Funhouse Mirror” 論文が指摘する 「個人差の圧縮」現象 は N=1,784 × 164 アウトカム規模で初めて検出された現象であり、本実験(N=1、誤答 2 問)から「整合する」と断ずるのは飛躍です。示唆的観察にとどめ、N を増やしてから再評価する のが正しい姿勢です。
Likert:n=3 のため強い結論は留保、±1 以内一致 2/3 は方向性のみ
Likert 3 問では、完全一致は 1 問(C1)、±1 以内では 2 問(C1 と C9)が一致しました。n=3 と極めて小さいため、強い結論は留保します。
C1(生活に不可欠=強くそう思う 5)は個人モデルも 5 で完全一致しています。「強い・極端な態度は的中しやすい」可能性はありますが、n=1 観察のため確証はありません。
C5(差分 2、本人 4 vs ツイン 2)は前節で詳述したとおり、アンケート範囲に含まれていないテーマ外の価値観情報(コスパ重視ライフスタイル)がプロフィールに反映されなかったことに起因する誤答 と考えられます。「中央寄りに過小評価」というよりは「部分プロフィールでの合理的推論が本人の実態と乖離した」事例です。
C9(差分 1、本人 5 vs ツイン 4)は ±1 以内に収まっており、本人の強い肯定をツインが「やや弱め」に受け取った形。n=1 のため傾向と呼ぶには弱いですが、強度のキャリブレーションが課題の可能性があります。
実務含意としては、Likert 系では完全一致よりも「±1 以内」を許容範囲とする運用が現実的という方針自体は変わりませんが、本実験の数値はあくまで予備的なシグナルです。
主要な知見
質問タイプによって精度の様相が異なることが本実験の主たる観察です。「個人モデルの精度」を単一の集計値で表現できず、質問タイプごとに切り分けて評価する設計が必要。本実験ではホールドアウトに頻度系(A 系列)が含まれなかったため、頻度評価は未実施のままです。
定性評価:チャットインタフェースでの自由対話
定量バックテストとは別に、構築した個人モデルに対して自由形式で問い合わせを行えるチャットインタフェースを試験実装し、定性的な評価も実施しました。アンケートのホールドアウト 10 問では現れない、より自由度の高い問いに対して個人モデルがどの程度「本人らしさ」を再現できるかを確認することが目的です。
下記は、筆者自身の個人モデルに対して「ホットスナックの新商品コンセプト」を提示し、購入意向を尋ねた際の応答です。マーケティングリサーチの実務で頻出する「新商品評価」のシミュレーションに相当します。
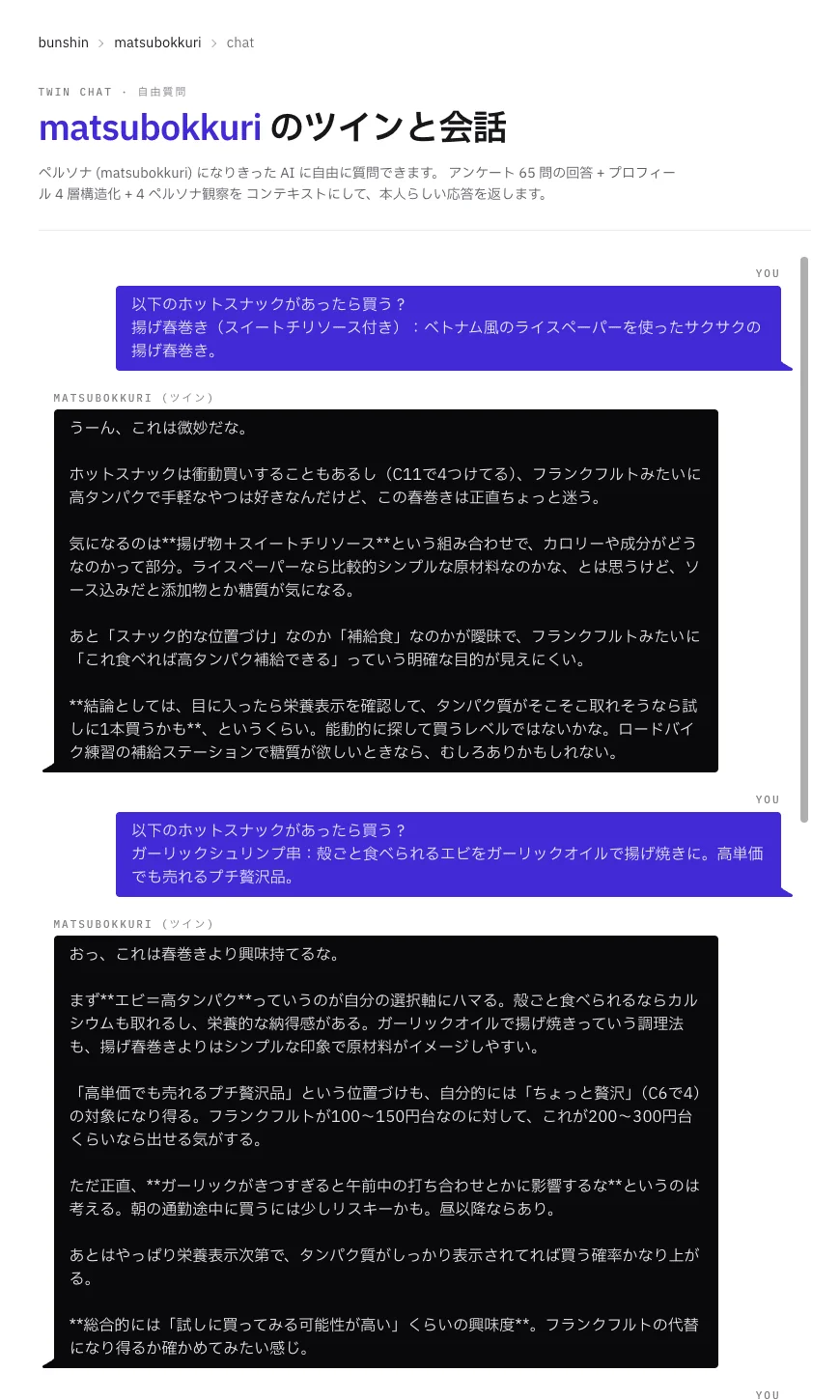
応答内容のうち、特筆すべき点は以下です。
- アンケート回答の参照と引用:「C11 で 4 つけてる」(衝動買い傾向)「C6 で 4」(プチ贅沢への態度)といった、学習用の自分のアンケート回答を根拠として引用しながら推論している
- 趣味・生活文脈の統合:「ロードバイク練習の補給ステーション」「朝の通勤途中に買うには少しリスキー」など、プロフィール記述に含まれる生活パターンを商品評価の文脈に持ち込んでいる
- 価格感度の具体的な数値化:「フランクフルトが 100〜150 円台なのに対して、200〜300 円台くらいなら出せる」と、参照価格付きで購買意思決定を言語化
- 商品ごとの反応の差別化: 揚げ春巻きには「微妙だな」、ガーリックシュリンプ串には「春巻きより興味持てるな」と、商品コンセプト依存で態度が変化
- 栄養成分・タンパク質含有量への一貫した関心: 両商品の評価で繰り返し言及されており、プロフィールに含まれる健康意識・運動習慣が一貫した判断軸として機能している
筆者自身の実態に照らすと、これは かなり正確な再現 です。価格感度の数値や、運動習慣と紐付いたタンパク質志向、朝の予定との兼ね合いといった具体性のある推論は、プロフィール記述とアンケート回答が適切に統合され、新規の問いに対する応答に投影された結果と考えられます。
定量評価と定性評価の落差(仮説)
本実験における観察を素直に並べると、強制選択(ホールドアウト 10 問)と自由対話(チャット)の間に応答の質の落差が見えます。前者では完全一致が限定的だった一方、後者では学習側のアンケート回答番号まで引用しながら本人らしい推論が出力されました。
| 評価モード | 出力形式 | 本実験での観察 |
|---|---|---|
| 強制選択(単一選択・Likert) | 離散的な選択肢 | N=1 で確証は得られず(n=3〜7) |
| 自由生成(チャット) | 任意のテキスト | プロフィール・既回答を統合した本人らしい応答(n=数件の定性観察) |
この落差は 「個人モデルは語ること(自由生成)は得意で、選ぶこと(強制選択)は苦手」 という仮説として読めます。LLM の生成タスクと分類タスクの性質差を考えると、それなりにありそうな仮説ですが、現時点で本仮説を強く支持する統計的証拠は得られていません(N=1、定性は数件のみ)。
仮にこの仮説が N を増やしても保持されるなら、用途設計には次の含意が考えられます。
- 定量集計を目的とするアンケート代替: 強制選択型の質問では慎重な質問選別が必要
- インタビュー代替・コンセプト評価: 自由形式での意見聴取であれば、本人らしさの再現は実用に資する可能性
いずれも N≥5 規模での追検証で確かめるべき論点です。
今後の課題と次のアクション
本検証(N=1 予備実験)から明らかになった課題を、評価フレーム / 設問設計 / 個人モデル本体 / 追検証すべき仮説 / ツール改善 の 5 カテゴリで整理します。次の実装サイクルへの input として使います。
A. 評価フレームの再設計
| # | 課題 | 観察根拠 | アクション |
|---|---|---|---|
| A1 | N=1 で lift が退化する | baselines.ts のコメントどおり、母集団最頻値 = 本人回答となりベースラインが崩れる | N≥5 規模に被験者を拡張してベースラインを意味化 |
| A2 | Self-consistency 未測定 | ツインの理論的上限が分からないため lift の分母も解釈が不安定 | 本人 1〜2 週間後の再回答 を取得する運用フローを実装 |
| A3 | ホールドアウトに頻度系(A 系列)が含まれない | run #17 ではランダム抽出の結果 frequency6 がゼロに | ホールドアウト分割を 質問タイプ別 stratified sampling に変更 |
| A4 | lift 退化状態の警告がない | ダッシュボードに過去計算の lift が残存し誤読を招く | N=1 / ベースライン退化を 検出して UI に警告 を出す |
| A5 | 強制選択以外の評価モードがない | D5 のように単一選択が情報を圧縮する設問では accuracy が下振れする | multi-select の Jaccard / 尤度回答 / Self-consistency 正規化 を追加 |
| A6 | 本文の lift 定義と実装が不一致 | 設計は Self-consistency 上限を分母にしたかったが、実装は 1 - baseline | 設計を実装に合わせるか、Self-consistency を取得後に実装を更新 |
B. 設問設計の改善
| # | 課題 | 観察根拠 | アクション |
|---|---|---|---|
| B1 | アンケートが特定テーマに閉じている | C5 誤答の原因。コスパ重視の価値観が「コンビニ外でどう発現するか」が学習できない | テーマ横断プロフィール質問 を追加(価値観の他カテゴリでの発現、買い物全体の優先順位など) |
| B2 | 単一選択が状況依存行動を圧縮する | D5 誤答。「メインケース vs サブケース」の両立が不可 | 複数選択や尤度回答 を許容する設問形式の導入 |
| B3 | 低エントロピー設問が精度を過大評価 | 9 割が同一回答する設問では一律回答でも accuracy が稼げる | パイロット段階(社員 5〜10 名)でエントロピー検証 → 本番除外 |
| B4 | 質問文の言い換えに対する脆弱性 | プロンプト v1→v2→v3 で結果が顕著に変動(文献も指摘: Brucks & Toubia 2025) | 同一質問の 複数言い換えバリアント を用意し、応答の一貫性を計測 |
| B5 | F 系列(自由記述)の学習データ寄与が未検証 | 学習側に 7 問の long_text、1 問の url_list があるが、精度寄与は未測定 | F 系列を ablation して効果検証 |
C. 個人モデル本体の改善
| # | 課題 | 観察根拠 | アクション |
|---|---|---|---|
| C1 | プロフィール明示性不足時の “不明” fallback | B7 誤答。本人は明確な選好を持つが、プロフィール記述に明示が無いと「わからない」を返す | プロフィール推論段階で暗黙の選好を推察 するステップを追加(既存回答から推察した選好を構造化プロフィールに格納) |
| C2 | 強い意見の強度キャリブレーション | C9 で本人 5 をツイン 4 と過小評価。±1 以内には収まるが系統的偏りの可能性 | 学習側既回答の強度分布を プロンプトに明示 して校正、または post-hoc calibration |
| C3 | tatemae 問題(規範回答収束)の技術対策が未着手 | 「Honne モデル」は命名のみで、tatemae 対策の具体的アーキテクチャは未実装 | プロンプトレベル(建前回避指示)、データ前処理レベル(自由記述からの本音抽出)、評価レベル(tatemae 度メトリクス)の 3 層で検討 |
| C4 | プロンプトのバージョン管理が手動 | v1 / v2 / v3 を運用中だが、自動 A/B テスト基盤は無い | プロンプト version 管理と robustness テストの 自動化 |
| C5 | Claude Opus との比較未実施 | スタック表で「Opus 比較検証中」と記載しているが未着手 | Sonnet 4.6 vs Opus を 同じプロンプト・同じ被験者 で比較 |
D. 観測されたシグナル別の追検証
| # | 仮説 | 観察根拠 | 追検証の設計 |
|---|---|---|---|
| D1 | レイヤー仮説: 既存研究は L1、消費者調査は L2-3 で精度が出にくい | 本稿の 4 層モデルでの整理 | N≥5 で 質問タイプ × レイヤー の精度マトリクス取得 |
| D2 | 強制選択 vs 自由生成の非対称性: 「選ぶ」より「語る」のほうが本人らしい | D1/D5 リーゾニングとチャット応答の落差 | 同一被験者で 強制選択と自由対話を並行計測、評価者判定で本人らしさをスコア化 |
| D3 | リーゾニングの質と lift の独立性 | D1 は質の高いリーゾニングだが多数派回答と一致、D5 はリーゾニングが妥当でも DIFF | リーゾニング品質を 独立メトリクス として取得(評価者ルブリック、または LLM-as-a-judge) |
| D4 | 本人の単発回答の noise(test-retest reliability) | D5 で本人もメイン vs サブで揺れる可能性 | Self-consistency 計測時に 本人のブレ幅 をベースラインとして lift から差し引く |
E. ダッシュボード・ツール改善
| # | 機能 | 現状 | 拡張 |
|---|---|---|---|
| E1 | lift 退化警告 | 無し | N=1 または baseline degenerate を 自動検出して UI 警告 |
| E2 | リーゾニングの構造化検索 | 文字列として保存のみ | どの プロフィール層・どの既回答 ID を参照したかをパース・集計 |
| E3 | 設問単位の精度ビュー | 集計平均のみ | 質問タイプ × レイヤー マトリクス、外した質問の reasoning 一覧 |
| E4 | エントロピー検証ツール | 無し | パイロット集団からの 設問別エントロピー算出 と除外候補リスト |
| E5 | 評価者判定 UI | 既存(/verdict) | 「ツインの誤答が本人のブレ範囲内か」を 第三者が判定 できる UI 拡張 |
優先順位(直近の実装サイクル)
最初の N≥5 拡張に向けて、特に直近で取り組むべきは以下です。
- A1(N 拡張)+ A2(Self-consistency 取得運用)+ A3(stratified ホールドアウト) — 評価が成立する状態を作る
- A4(lift 退化警告)+ E1(UI 警告) — 数値の誤読を防ぐ
- B1(テーマ横断質問)+ B3(エントロピー検証) — 設問起因の精度低下を抑える
- C1(暗黙選好の構造化) — B7-type 誤答を抑える
中期では C3(tatemae 技術対策)、D1(レイヤー仮説検証)、D2(非対称性仮説検証)に取り組み、長期で商用化への整合性検証を進めます。
まとめ
- 本稿では LLM ベースの個人モデルでアンケート回答を自動化する PoC「bunshin」の構築と、N=1 の予備実験を報告しました
- 既存研究(Park 2024、Toubia 2025、Toubia 2026)の知見を踏まえてコンビニ利用 65 問アンケートを設計し、ホールドアウト 10 問(単一選択 n=7、Likert n=3、頻度なし)でバックテストを実施
- 生指標は 単一選択 accuracy 71.4%(5/7)、Likert ±1 以内 66.7%(2/3)、MAE 1.0
- 自由対話形式のチャットインタフェースでは、価格感度・運動習慣・趣味との関連付けなど 本人らしい応答 が定性的に確認でき、強制選択と自由生成の間に再現性の非対称性 がある可能性が示唆されました(要追検証)
- 「個人モデルによる完全代替」は現実的ではなく、現時点で実用性を主張できる段階にはありません。本稿は エンジニアリング報告 + N=1 ケーススタディ という位置付けで読まれるのが妥当です
本領域は評価手法すら定まっていない発展途上の研究分野です。Toubia ラボが 2025 → 2026 で楽観論から自己批判へ転じたことからも、個人モデルの限界は早期に露呈すると見られます。本検証単体での主張は最小限にとどめ、N を増やしてからの再評価で初めて意味のある結論が出る という前提で位置付けます。
次の実装サイクルでは、前節「今後の課題と次のアクション」の優先順位(A1〜A4、B1・B3、C1)から着手します。
日本人特化の個人モデルは、海外の商用プレイヤー(Brox、Evidenza、Ditto 等)が未踏のポジションであり、参入余地は大きいですが、まずは方法論を確立することが優先です。
おまけ
グローバル商用プレイヤーの動向
LLM ベースの個人モデルの商用化は 2024-2026 にかけて急速に進行しており、価格帯は以下のとおりです。
| プレイヤー | 価格帯 | 主要クライアント |
|---|---|---|
| Brox | $100k/年〜 | 大手銀行、グローバル製薬 |
| Evidenza | $50-100k/年(推定) | BlackRock、JP Morgan、Microsoft、Dentsu |
| Ditto | $50-75k/年 | 非公開 |
| Synthetic Users | $2-27/respondent | 非公開 |